
The Transformer model, introduced in the paper “Attention is All You Need”, has literally transformed modern natural language processing (NLP) and ignited the (re-) emergence of whole new other AI fields (most notably Generative AI). The model’s power lies in its encoder-decoder architecture and the self-attention mechanism, which is amenable to extreme parallelisation and thus offers computationaly efficiency.
I’ve found that acquiring an intuitive understanding of the Transformer’s architecture is an iterative process, which, however, pays off in the end and helps understand the beauty and overall ‘simplicity’ (or not 😄) of the model. However, along with acquiring a strong technical understanding of the archicture, it massively helps to also gain a practical understanding of how sequences are actually processed and generated at each step. So, here we are – compiling some of my thoughts which I hope can help build a better intuition about what these models actualy do.
In this post, I’ll start by breaking down how the encoder and decoder interact during training, and how they work together to translate a small sentence from English to French. While I appreciate this might be ‘“common knowledge”, I also appreciate that Repetitio est mater studiorum 😊
1. The Transformer Architecture Overview
The Transformer model consists of two main components:
- Encoder: Processes the input sequence and generates context vectors.
- Decoder: Uses the encoder’s context vectors to generate the target sequence, one token at a time.
2. The Encoder: Processing the Input Sequence
What Does the Encoder Do?
The encoder takes the entire input sequence at once and transforms it into a set of context vectors. This representation captures the meaning and dependencies of the input sequence, which is crucial for generating the target sequence.
Encoder Input
For example, let’s consider the input sentence:
- Input Sentence:
"I am happy"
This entire sentence is fed into the encoder at once. Each word is converted into a vector representation (embedding) and then processed through multiple layers of self-attention and feed-forward networks.
Understanding the Encoder Output
The encoder generates context vectors for each token in the input sequence. These vectors capture the relationships between words in the sentence, allowing the model to understand the sentence holistically.
3. The Decoder: Generating the Target Sequence
What Does the Decoder Do?
The decoder generates the output sequence one token at a time. During training, it uses “teacher forcing,” where the actual target sequence (shifted to the right) is fed into the decoder to help it learn.
Initial Decoder Input
At the beginning of the decoding process, the decoder receives:
- Previous Tokens: The
<SoS>(Start of Sequence) token. - Context Vectors: The output from the encoder.
First Pass of the Decoder
- Decoder Input:
- Previous Tokens:
<SoS> - Context Vectors: Encoded representations of
"I am happy" - Decoder Output: The first token of the target sequence, which should be
"Je".
Subsequent Passes of the Decoder
For each subsequent pass, the decoder takes the previous tokens and the encoder’s context vectors to generate the next token:
Second Pass
- Decoder Input:
- Previous Tokens:
<SoS>, Je - Context Vectors: Encoded representations of
"I am happy" - Decoder Output: The next token,
"suis".
Third Pass
- Decoder Input:
- Previous Tokens:
<SoS>, Je, suis - Context Vectors: Encoded representations of
"I am happy" - Decoder Output: The next token,
"heureux".
The model generates the translation "Je suis heureux", having leveraged the context vectors from the encoder and the previously generated tokens. In general (for any other smaller or larger sequences), the process continues until the entire target sequence is generated.
4. The Tango Between Encoder and Decoder
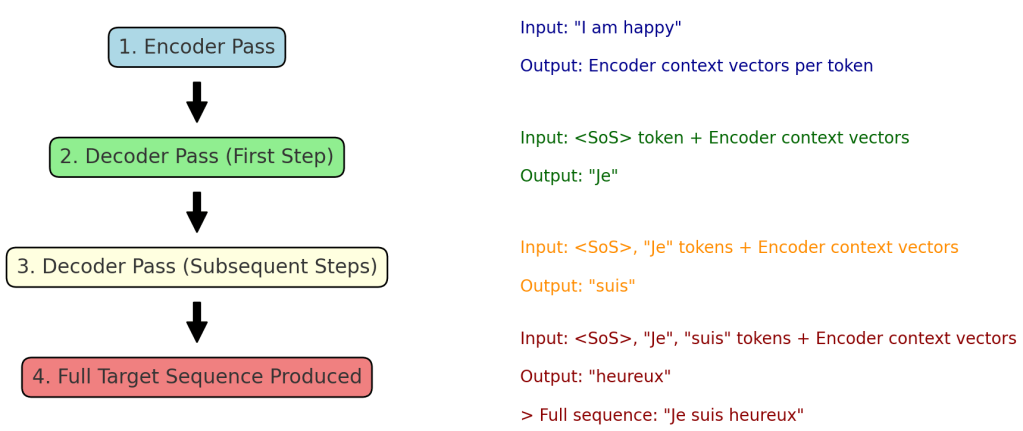
During training, the interaction between the encoder and decoder can be summarized as follows:
- Encoder Pass: The entire source sequence (
"I am happy") is processed by the encoder in a single pass, generating context vectors for each token. - Decoder Pass:
- First Step: The decoder receives the
<token and the encoder’s context vectors to generate the first target token (SoS>"Je"). - Subsequent Steps: For each step, the decoder takes the previously generated tokens and the context vectors to predict the next token, until the full target sequence is produced.
5. Training Process: Backpropagation and Weight Updates
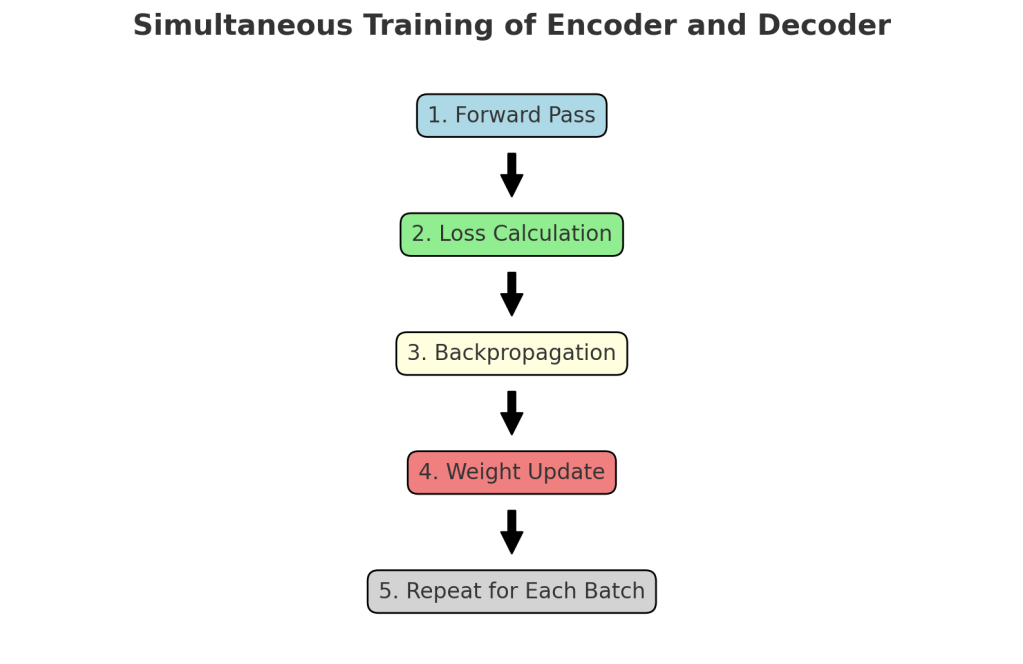
Simultaneous Training of Encoder and Decoder
The training process updates the weights of both the encoder and decoder simultaneously. Here’s how it works:
- Forward Pass:
- The encoder processes the input sequence, and the decoder uses the context vectors and the target sequence to generate predictions.
2. Loss Calculation:
- The loss is calculated by comparing the decoder’s predictions with the actual target sequence.
3. Backpropagation:
- The loss is backpropagated through the entire model, updating both the encoder and decoder weights.
4. Weight Update:
- The optimization algorithm (e.g., Adam) updates the weights to minimize the loss.
This process is repeated for each batch of data, gradually improving the model’s performance.
6. Bottom line
While all the above may seem straightforward, the intricate dance between the encoder and decoder —where context vectors and previously generated tokens inform each new prediction— reveals the nuanced and powerful mechanisms that make the Transformer so effective.
Special thanks goes to GPT-4o for the polishing and insightful nudges along the way 📚
If you’ve made it this far, I hope you’re walking away with a bit more clarity and appreciation for what these models actually do under the hood, so that you can apply them to your own domain! 🙂
References
- Vaswani, A., et al. (2017). Attention is All You Need. arXiv:1706.03762.

Leave a comment